















En la actualidad, los profesionales de la confiabilidad se enfrentan a diversas opciones relacionadas con tecnologías y métodos para detectar, solucionar y remediar problemas. La figura 1 es un ejemplo simple de las opciones disponibles para recopilar datos y tomar decisiones sobre el estado de la maquinaria y sus componentes.
El punto de partida lógico es siempre clasificar cuidadosamente los modos de falla tanto por su criticidad como por su probabilidad de ocurrencia. Para obtener más información sobre este tema, consulte mi artículo titulado “Un nuevo enfoque del análisis de criticidad para la lubricación de maquinaria”. Este método se conoce como análisis de modos de falla y efectos (FMEA, por sus siglas en inglés) y ha sido ampliamente documentado.
La clasificación de los modos de falla pone en marcha el proceso de ruta crítica para alcanzar decisiones optimizadas relacionadas con el monitoreo de la condición, seguidas de la respuesta o solución prescrita. Esta respuesta no debe ser simplemente correctiva, sino que también debe incorporar medidas proactivas para prevenir o restringir la recurrencia. El énfasis está puesto en decisiones y acciones optimizadas.
Es fácil optar por lo barato (ahorrar unos centavos y gastar en vano), pero también puede haber tentaciones en el otro extremo (un estado de exceso de confiabilidad), a menudo impulsado por el miedo a lo desconocido. El estado óptimo de referencia es una actividad de búsqueda de decisiones equilibradas. Después de todo, no se trata de maximizar la confiabilidad. No hay mayor fuente para encontrar este equilibrio que el conocimiento y la educación.
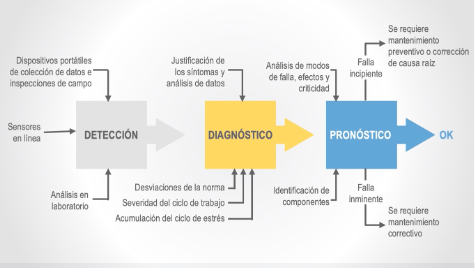
Figura 1. Un ejemplo de las opciones disponibles para recopilar datos
y tomar decisiones relacionadas con el estado de los equipos
Tabla de zonas de detección
La figura 2 muestra una matriz con colores que designan las zonas de detección de monitoreo de condiciones. Estas zonas se describirán con más detalle más adelante. Sin embargo, en términos simples, están destinadas a ayudar a concentrar las habilidades y los recursos donde existe la mayor necesidad. Esta matriz sopesa los beneficios del monitoreo de condición frente a los costos inherentes de la ejecución hábil y frecuente de su aplicación.
En la tabla de zonas de detección (TZD), las tres columnas que van de izquierda a derecha se relacionan con las habilidades, herramientas y métodos utilizados para realizar tareas de monitoreo de condición. La primera columna corresponde al monitoreo de condiciones de nivel máster y, por lo tanto, se lleva a cabo con precisión y habilidad experta.
La columna del medio muestra el monitoreo de condiciones en un nivel de habilidad más común o básico. La columna de la derecha muestra el monitoreo de condiciones realizado por personas no capacitadas y no calificadas. En este nivel, el monitoreo de condición es más una cuestión de conjeturas descabelladas y de ciencia ficción.
Las tres columnas no sólo se relacionan con el grado o profundidad de la capacitación y la experiencia, sino que también dependen en gran medida de otros factores como la cultura de confiabilidad, el acceso a la tecnología y las herramientas, y la disponibilidad de suficiente personal de monitoreo de condición.
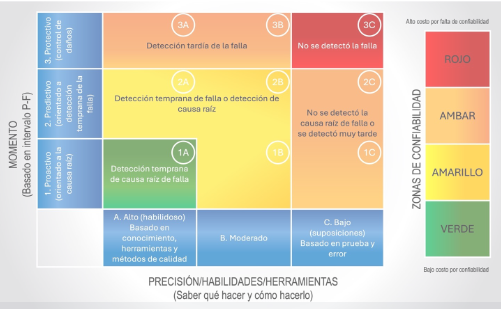
Figura 2. Tabla de zonas de detección
De estos factores, la cultura de confiabilidad es la que más influye en lo que hacen los técnicos y analistas de monitoreo de condiciones y en cómo lo hacen. Si corrige su cultura de confiabilidad, muchas otras cosas se solucionarán al mismo tiempo.
El poder de la frecuencia
La tabla de zonas de detección también muestra tres filas que designan la ubicación y el momento de las tareas de monitoreo de condiciones, que son igualmente importantes para el resultado. El momento del monitoreo de condiciones podría ser continuo (por ejemplo, un sensor en línea) con poca interacción humana o periódico mediante tareas de inspección y recopilación de datos, como con dispositivos portátiles.
La frecuencia de estas tareas tiene mucho que ver con los resultados obtenidos. Por supuesto, algunas máquinas pueden funcionar perfectamente sin ningún tipo de supervisión de condición (funcionamiento hasta la falla).
Considere la siguiente analogía: independientemente de la experiencia del pescador, no se capturará ningún pez si su anzuelo no está en el agua. Lo mismo sucede con la detección de causas fundamentales y fallas activas de las máquinas. Los técnicos solo pueden detectarlas si están realizando tareas de monitoreo de condiciones que se enfoquen de manera efectiva en los modos de falla conocidos.
Esta periodicidad es la que permite que la inspección por parte de un operador o técnico bien capacitado tenga una ventaja sobre el monitoreo de condiciones basado en la tecnología. Por ejemplo, el análisis de aceite en una mirilla se puede realizar diariamente, a diferencia del análisis de aceite de laboratorio, el análisis de vibraciones y el ultrasonido, que a menudo se programan en intervalos mensuales o trimestrales.
El monitoreo de condiciones realizado casi en tiempo real mediante sensores integrados, al estilo de la Internet Industrial de las Cosas (IioT, por sus siglas en inglés), puede brindar una ventaja igual o superior.
Como es de esperar, la ubicación tiene que ver con el punto óptimo de inspección o de recopilación de datos. Por ejemplo, en el análisis de aceite, ¿cuál es la ubicación óptima para extraer una muestra? Del mismo modo, ¿cuáles son los puntos críticos al realizar las inspecciones? ¿Qué sucede con la ubicación en relación con el uso de pistolas de calor y termografía infrarroja?
Obviamente, se desea un intervalo PF largo, que depende en gran medida de la frecuencia de monitoreo. Esto ayuda a cerrar la brecha entre el punto de detección y el punto de inicio de la falla. El uso del monitoreo de condiciones para detectar y erradicar las causas raíz de la falla produce un intervalo PF negativo. ¿Qué podría ser más ideal?
Por lo tanto, el monitoreo de condiciones realizado con una alta frecuencia será más efectivo y mucho más proactivo (orientado a la causa raíz). Esta es la base estratégica del mantenimiento proactivo.
Definiciones de zonas de detección
Las cuatro zonas de detección están codificadas por colores de la siguiente manera:
Zona verde (proactiva): la detección temprana de la causa raíz en esta zona está relacionada con la inspección frecuente en los lugares correctos utilizando las herramientas y los métodos adecuados, así como habilidades expertas.
Zona amarilla (predictiva): esta zona puede pasar por alto algunas causas raíz, pero si se ejecuta correctamente, puede detectar fallas y problemas de fallas incipientes de manera temprana (cerca del momento de su inicio). Dependerá de una inspección frecuente combinada con técnicas hábiles y herramientas efectivas.
Zona ámbar (protectiva): el monitoreo de condición en esta zona detecta fallas antes de que se conviertan en fallas catastróficas y daños colaterales. Algunos pueden llamar a esto monitoreo de condición justo a tiempo, pero por muchas razones, es una pendiente resbaladiza en el mejor de los casos. Si bien puede ser posible una detección previa a la falla, en otros casos el período de desarrollo de la falla puede ser demasiado corto para lograr una advertencia práctica. Por supuesto, también existen esas molestas fallas de muerte súbita.
Zona roja (avería): es la falla operativa completa.
Codificación de la zona de detección
A continuación, asigne los modos de falla a las zonas de detección óptimas y de mejor ajuste. Comience por trabajar en la clasificación de modos de falla, comenzando con las máquinas críticas para el proceso. Coloque cada modo de falla en una o dos zonas dentro de la TZD.
Los modos de falla de alto rango se deben asignar a la zona verde. Otros pueden encajar dentro de la zona amarilla. Los modos de falla de menor rango se pueden colocar en las zonas amarilla o ámbar.
Apliquemos esto a un ejemplo hipotético. Un compresor centrífugo de alta velocidad ha tenido problemas crónicos con fallas en los cojinetes. Un ejercicio de análisis de modos de falla y efectos (FMEA, por sus siglas en inglés) clasificó al barniz y al lodo como la causa raíz aparente en la mayoría de los casos.
La causa raíz principal fue la mala liberación del aire del lubricante, que se agravó debido a las fuentes de aire atrapado. El calor por la compresión adiabática del aire atrapado fue la causa del barniz.
La figura 3 reformula la TZD para ilustrar cómo el monitoreo de condiciones puede detectar y responder a este tipo de falla de diferentes maneras. Se utilizó el ejemplo del barniz porque he visto las acciones y los resultados que se enumeran en las celdas de la tabla en muchos casos del mundo real. A continuación, se incluye una breve descripción de cada una de las celdas.
Celda 1A: la inspección y el análisis de aceite frecuentes y hábiles detectan y reconocen el problema de aireación. Se erradicaron las causas raíz (inducción de aire y aceite contaminado de forma cruzada).
Celdas 2A y 3A: la principal diferencia aquí es la detección y respuesta tardía a la aireación y la necesidad de abordar el problema del barniz que se generó. La detección temprana evita la formación de barniz. La detección tardía requiere remover el barniz del aceite y la máquina. Esto genera costos y riesgos adicionales.
Celda 1B: aquí, la falta de capacitación sobre el barniz y la aireación resultó en tratar el síntoma (desgasificación) y no la causa raíz (la fuente de los problemas de aire atrapado y liberación de aire).
Celdas 2B y 3B: si el problema de aireación no se detecta ni se soluciona, rápidamente se convierte en un problema de barniz y lodo. Remover el barniz y el lodo, y luego cambiar el aceite no es más que una solución a corto plazo. La causa raíz sigue sin controlarse, por lo que la aireación y el barniz volverán a aparecer pronto.
Celda 1C: si bien se detectó la aireación, la solución improvisada de cambiar el aceite y el filtro no sirvió para brindar una solución real. ¿Cuántas veces se necesita cambiar el aceite para solucionar un problema de aire atrapado?
Celda 2C: el retraso en el tiempo y las habilidades deficientes para monitorear el estado hacen que se detecte barniz en etapa avanzada, pero no la causa raíz. Una vez que hay un alto potencial de barniz, los días del compresor están contados.
Celda 3C: una falla en el cojinete y su desmontaje revelaron lodos en los conductos de aceite y un flujo de aceite restringido al cojinete (falta de aceite). El personal de mantenimiento declaró de inmediato que el aceite estaba defectuoso y que esa era la causa de la falla del cojinete. Se despidió al proveedor de aceite y se puso en servicio un aceite nuevo. ¿Se despedirá pronto también al segundo proveedor de aceite?
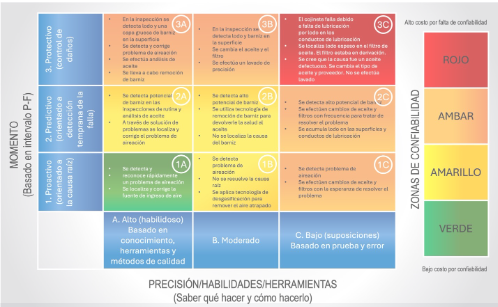
Figura 3. Tabla de zonas de detección utilizada para ilustrar cómo el monitoreo de condiciones puede detectar y responder a fallas de diferentes maneras.
Los cinco críticos
¿Es necesario que una persona utilice la TZD para optimizar el monitoreo de condición? Absolutamente no. Sin embargo, la tabla le ayuda a comprender las consecuencias de un monitoreo de condición deficiente. Como he visto durante años, cualquier programa de análisis de aceite no es lo suficientemente bueno. Lo mismo sucede con la inspección y muchas otras tecnologías y métodos de monitoreo de condición. Hacerlo bien o hacerlo bien puede producir resultados muy diferentes.
Piense en los cinco puntos críticos como una forma sencilla de definir lo que significa “hacer un buen monitoreo de condiciones”. Son los siguientes:
El qué: sepa qué está intentando detectar o analizar. ¿Es un síntoma o una causa raíz? ¿Es medible o verificable? ¿Es controlable?
El por qué: sepa por qué es importante. ¿Cómo afecta la confiabilidad y la disponibilidad de los activos? ¿Cómo su detección y control reduce los costos del ciclo de vida, el consumo de energía y el impacto al medio ambiente? ¿Cómo aumenta la seguridad?
El lugar: ¿cuál es el lugar más eficaz para encontrar lo que se intenta detectar? ¿Cómo se puede mejorar esta ubicación y hacerla más conveniente (instalando ventanas de inspección, por ejemplo)?
El cómo: ¿qué habilidades, métodos y herramientas serán necesarios para optimizar la detección y el control? ¿Cómo se pueden detectar las causas fundamentales antes de que se produzcan fallas? ¿Cómo se pueden detectar los síntomas de fallas de manera temprana para extender el intervalo PF y hacer que la remediación sea conveniente sin una pérdida significativa de la vida útil restante (RUL, por sus siglas en inglés)?
El cuándo: ¿cuándo se deben realizar las tareas de monitoreo de condición para lograr los objetivos de confiabilidad? ¿Cómo pueden desempeñar un papel efectivo las inspecciones diarias y el monitoreo en línea?
El monitoreo de condiciones es como una búsqueda del tesoro. La mayor diversión está en la búsqueda. Y sí, hay un tesoro al final.
Jim Fitch, Noria Corporation. Traducción por Roberto Trujillo Corona, Noria Latín América